Generate context-specific representations from ChromBERT¶
Note: The remaining examples show Bash command-line usage only for extracting region embeddings.
embed_region subcommand: Generate region embeddings for input regions.
For the Python API, see `examples/api/embed_region.ipynb <../api/embed_region.ipynb>`__.
If you need to use Apptainer container, please refer to the `apptainer_use.ipynb <apptainer_use.ipynb>`__ tutorial for detailed instructions on using apptainer exec with chrombert-tools.
For more details, please refer to the `embed_region <https://chrombert-tools.readthedocs.io/en/latest/commands/embed_region.html>`__ command documentation
Generate region embeddings (pre-trained and general)¶
[1]:
### options parameter
!chrombert-tools embed_region -h
Usage: chrombert-tools embed_region [OPTIONS]
Generate region embeddings for specified regions or gene promoter regions
Options:
--region FILE Region BED file.
--gene TEXT Gene symbols or IDs separated by ';'.
--cell-type-bw FILE Cell type accessibility BigWig file.
--cell-type-peak FILE Cell type accessibility Peak BED file.
--ft-ckpt FILE Fine-tuned checkpoint. If provided, skip
fine-tuning.
--odir DIRECTORY [default: ./output]
--oname TEXT [default: embedding]
--genome [hg38|mm10] [default: hg38]
--resolution [1kb|200bp|2kb|4kb]
[default: 1kb]
--mode [fast|full] Used when training cell-specific model.
[default: fast]
--batch-size INTEGER [default: 4]
--chrombert-cache-dir DIRECTORY
[default: ~/.cache/chrombert/data]
--chrombert-region-file FILE
--chrombert-region-emb-file FILE
--chrombert-gene-meta FILE
-h, --help Show this message and exit.
[2]:
%%bash
# --region: Input regions to embed.
# --odir: Output directory.
# --genome: Genome to use.
# --resolution: Resolution of the input regions.
chrombert-tools embed_region \
--region ../data/umap_region_1kb_downsample.bed \
--odir ./output_emb_region_1kb \
--genome hg38 \
--resolution 1kb
Region summary - total: 3000, overlapping with ChromBERT: 3000 (one region may overlap multiple ChromBERT regions, we keep overlaps with ≥50% coverage of either the ChromBERT bin or the input region), non-overlapping: 0
Using cached region embeddings...
Finished!
Focus region summary - total: 3000, overlapping with ChromBERT: 3000, non-overlapping: 0
Note: It is possible for a single region to overlap multiple ChromBERT regions.
Overlapping regions BED file: ./output_emb_region_1kb/overlap_region.bed
Non-overlapping regions BED file: ./output_emb_region_1kb/no_overlap_region.bed
Region embeddings saved to: ./output_emb_region_1kb/region_emb_embedding.npy
Embedding type: general
[3]:
import numpy as np
import pandas as pd
[4]:
# overlap_region_emb:
# Region embedding array with shape ``(n_regions, 768)``. Each row corresponds to one ChromBERT bin overlapping the input regions.
overlap_region_emb = np.load("./output_emb_region_1kb/region_emb_embedding.npy")
print(overlap_region_emb.shape)
# overlap_region.bed: Input regions that overlap ChromBERT bins.
# Contains columns: chrom, start, end, build_region_index
# model_input.tsv: Input regions that overlap ChromBERT bins.
# Contains columns: chrom, start, end, build_region_index, start_input, end_input
overlap_region = pd.read_csv("./output_emb_region_1kb/model_input.tsv",sep='\t')
len(overlap_region),overlap_region.head()
(3000, 768)
[4]:
(3000,
chrom start end build_region_index start_input end_input
0 chr1 54000 55000 6 54000 55000
1 chr1 916000 917000 213 916000 917000
2 chr1 960000 961000 255 960000 961000
3 chr1 1004000 1005000 296 1004000 1005000
4 chr1 1013000 1014000 305 1013000 1014000)
[5]:
# Map each region to its user-defined annotation class
region_anno = pd.read_csv("../data/umap_region_1kb_downsample.bed",sep="\t",header=None,names=["chrom","start_input","end_input","build_region_index","anno"])
overlap_region = overlap_region.merge(region_anno[["chrom","start_input","end_input","anno"]],on=["chrom","start_input","end_input"])
overlap_region
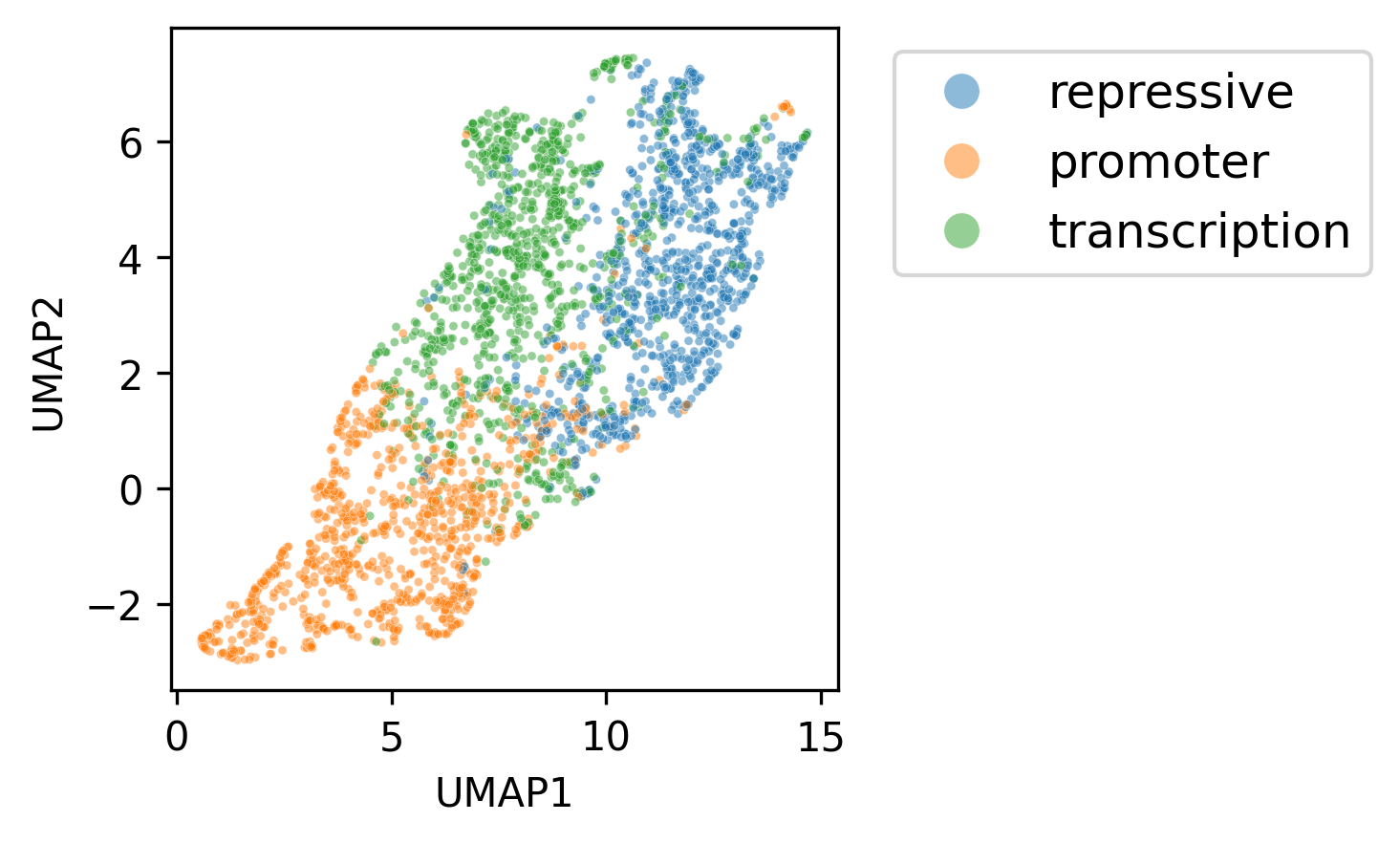
# umap plot
from chrombert_tools import umap_plot
umap_plot(overlap_region_emb, overlap_region["anno"], "./output_emb_region_1kb")
/mnt/Storage/home/chenqianqian/miniconda3/envs/chrombert/lib/python3.9/site-packages/umap/umap_.py:1952: UserWarning: n_jobs value 1 overridden to 1 by setting random_state. Use no seed for parallelism.
warn(
Generate gene (promoter region) embeddings¶
[6]:
%%bash
# --gene: Gene names or ENSEMBL IDs to embed.
# --odir: Output directory.
# --genome: Genome to use.
# --resolution: Resolution of the input regions.
chrombert-tools embed_region \
--gene "ENSG00000170921;TANC2;ENSG00000200997;DPYD;SNORA70;tp53;brd4" \
--odir "./output_emb_genes" \
--genome hg38 \
--resolution 1kb
Using cached region embeddings for gene pooling...
Finished!
Note: All gene names were converted to lowercase for matching.
Gene count summary - requested: 7, matched: 7, not found: 0
Matched gene meta saved to: ./output_emb_genes/overlap_genes_meta.tsv
Gene embeddings saved to: ./output_emb_genes/gene_emb_embedding.pkl
Embedding type: general
[7]:
# gene_emb.pkl: Python dictionary mapping each matched gene to a 768-dimensional embedding.
import pickle
with open("./output_emb_genes/gene_emb_embedding.pkl", "rb") as f:
gene_emb_dict = pickle.load(f)
for key, value in gene_emb_dict.items():
print(key, value.shape)
ensg00000170921 (768,)
tanc2 (768,)
ensg00000200997 (768,)
dpyd (768,)
snora70 (768,)
tp53 (768,)
brd4 (768,)
Generate cell-type-specific embeddings¶
We use cell-type-specific chromatin accessibility peak and signal files as input.
The embed_region subcommand uses these data to build a cell-type-specific model and generate cell-type-specific embeddings.
[ ]:
# download myoblast
# Myoblast cell-type-specific chromatin accessibility peak and signal files
import subprocess,os
if not os.path.exists('../data/myoblast_ENCFF647RNC_peak.bed'):
cmd = f'wget https://www.encodeproject.org/files/ENCFF647RNC/@@download/ENCFF647RNC.bed.gz -O ../data/myoblast_ENCFF647RNC_peak.bed.gz'
subprocess.run(cmd, shell=True)
cmd = f"gzip -d ../data/myoblast_ENCFF647RNC_peak.bed.gz"
subprocess.run(cmd, shell=True)
# import subprocess
if not os.path.exists('../data/myoblast_ENCFF149ERN_signal.bigwig'):
cmd = f'wget https://www.encodeproject.org/files/ENCFF149ERN/@@download/ENCFF149ERN.bigWig -O ../data/myoblast_ENCFF149ERN_signal.bigwig'
subprocess.run(cmd, shell=True)
[ ]:
# We only use the first 100 lines of the peak file for demonstration
!head -n 100 ../data/myoblast_ENCFF647RNC_peak.bed > ../data/myoblast_ENCFF647RNC_peak_100.bed
[ ]:
%%bash
# --region: Input regions to embed.
# --odir: Output directory.
# --genome: Genome to use.
# --resolution: Resolution of the input regions.
# --cell-type-bw: Cell-type-specific bigwig file.
# --cell-type-peak: Cell-type-specific peak file.
export CUDA_VISIBLE_DEVICES=0
chrombert-tools embed_region \
--region ../data/myoblast_ENCFF647RNC_peak_100.bed \
--odir ./output_cell_specific_emb_train \
--genome hg38 \
--resolution 1kb \
--cell-type-bw ../data/myoblast_ENCFF149ERN_signal.bigwig \
--cell-type-peak ../data/myoblast_ENCFF647RNC_peak.bed
Preparing dataset ...
Region summary - total: 373422, overlapping with ChromBERT: 368260 (one region may overlap multiple ChromBERT regions, we keep overlaps with ≥50% coverage of either the ChromBERT bin or the input region), non-overlapping: 7920
Total regions: 324690
Fast mode: downsampling to 20k regions
Fine-tuning cell-specific model...
[Attempt 0/2] seed=55
Load pretrained ckpt /mnt/Storage/home/chenqianqian/.cache/chrombert/data/checkpoint/hg38_6k_1kb_pretrain.ckpt successfully!
/mnt/Storage/home/chenqianqian/miniconda3/envs/chrombert/lib/python3.9/site-packages/torchmetrics/utilities/prints.py:43: UserWarning: Metric `SpearmanCorrcoef` will save all targets and predictions in the buffer. For large datasets, this may lead to large memory footprint.
warnings.warn(*args, **kwargs)
Using bfloat16 Automatic Mixed Precision (AMP)
GPU available: True (cuda), used: True
TPU available: False, using: 0 TPU cores
HPU available: False, using: 0 HPUs
You are using a CUDA device ('NVIDIA A100-PCIE-40GB') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
Loading `train_dataloader` to estimate number of stepping batches.
/mnt/Storage/home/chenqianqian/miniconda3/envs/chrombert/lib/python3.9/site-packages/lightning/pytorch/utilities/model_summary/model_summary.py:231: Precision bf16-mixed is not supported by the model summary. Estimated model size in MB will not be accurate. Using 32 bits instead.
| Name | Type | Params | Mode
---------------------------------------------------
0 | model | ChromBERTGeneral | 62.8 M | train
---------------------------------------------------
18.9 M Trainable params
43.9 M Non-trainable params
62.8 M Total params
251.095 Total estimated model params size (MB)
153 Modules in train mode
0 Modules in eval mode
/mnt/Storage/home/chenqianqian/miniconda3/envs/chrombert/lib/python3.9/site-packages/lightning/pytorch/trainer/connectors/data_connector.py:484: Your `val_dataloader`'s sampler has shuffling enabled, it is strongly recommended that you turn shuffling off for val/test dataloaders.
Epoch 0: 20%|██ | 800/4000 [02:18<09:15, 5.76it/s, v_num=0]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Metric default_validation/pcc improved. New best score: 0.270
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.26it/s]
Epoch 0: 40%|████ | 1600/4000 [05:02<07:33, 5.30it/s, v_num=0, default_validation/r2=-0.0472, default_validation/pcc=0.270, default_validation/scc=0.196, default_validation/mae=0.222, default_validation/mse=0.121, default_validation/rmse=0.348, default_validation/mean=0.0806, default_validation/median=0.0757]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.23it/s]
Epoch 0: 60%|██████ | 2400/4000 [07:46<05:11, 5.14it/s, v_num=0, default_validation/r2=0.0133, default_validation/pcc=0.251, default_validation/scc=0.231, default_validation/mae=0.201, default_validation/mse=0.120, default_validation/rmse=0.346, default_validation/mean=0.118, default_validation/median=0.120]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Metric default_validation/pcc improved by 0.161 >= min_delta = 0.01. New best score: 0.432
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.09it/s]
Epoch 0: 80%|████████ | 3200/4000 [10:34<02:38, 5.04it/s, v_num=0, default_validation/r2=0.045, default_validation/pcc=0.432, default_validation/scc=0.404, default_validation/mae=0.184, default_validation/mse=0.117, default_validation/rmse=0.342, default_validation/mean=0.0654, default_validation/median=0.0396]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Metric default_validation/pcc improved by 0.067 >= min_delta = 0.01. New best score: 0.498
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.14it/s]
Epoch 0: 100%|██████████| 4000/4000 [13:18<00:00, 5.01it/s, v_num=0, default_validation/r2=0.206, default_validation/pcc=0.498, default_validation/scc=0.461, default_validation/mae=0.176, default_validation/mse=0.100, default_validation/rmse=0.316, default_validation/mean=0.116, default_validation/median=0.0732]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Metric default_validation/pcc improved by 0.096 >= min_delta = 0.01. New best score: 0.595
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.16it/s]
Epoch 1: 20%|██ | 800/4000 [02:19<09:19, 5.72it/s, v_num=0, default_validation/r2=0.316, default_validation/pcc=0.595, default_validation/scc=0.531, default_validation/mae=0.158, default_validation/mse=0.0776, default_validation/rmse=0.279, default_validation/mean=0.112, default_validation/median=0.0549]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Metric default_validation/pcc improved by 0.082 >= min_delta = 0.01. New best score: 0.676
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.10it/s]
Epoch 1: 40%|████ | 1600/4000 [05:03<07:35, 5.27it/s, v_num=0, default_validation/r2=0.403, default_validation/pcc=0.676, default_validation/scc=0.609, default_validation/mae=0.187, default_validation/mse=0.0683, default_validation/rmse=0.261, default_validation/mean=0.235, default_validation/median=0.202]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Metric default_validation/pcc improved by 0.124 >= min_delta = 0.01. New best score: 0.800
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.21it/s]
Epoch 1: 60%|██████ | 2400/4000 [07:47<05:11, 5.14it/s, v_num=0, default_validation/r2=0.534, default_validation/pcc=0.800, default_validation/scc=0.705, default_validation/mae=0.130, default_validation/mse=0.0541, default_validation/rmse=0.233, default_validation/mean=0.102, default_validation/median=0.040]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Metric default_validation/pcc improved by 0.035 >= min_delta = 0.01. New best score: 0.835
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.21it/s]
Epoch 1: 80%|████████ | 3200/4000 [10:30<02:37, 5.07it/s, v_num=0, default_validation/r2=0.697, default_validation/pcc=0.835, default_validation/scc=0.775, default_validation/mae=0.109, default_validation/mse=0.035, default_validation/rmse=0.187, default_validation/mean=0.172, default_validation/median=0.0654]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Metric default_validation/pcc improved by 0.036 >= min_delta = 0.01. New best score: 0.871
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.02it/s]
Epoch 1: 100%|██████████| 4000/4000 [13:45<00:00, 4.84it/s, v_num=0, default_validation/r2=0.756, default_validation/pcc=0.871, default_validation/scc=0.804, default_validation/mae=0.102, default_validation/mse=0.0306, default_validation/rmse=0.175, default_validation/mean=0.168, default_validation/median=0.0669]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Validation DataLoader 0: 100%|██████████| 250/250 [00:27<00:00, 9.02it/s]
Epoch 2: 20%|██ | 800/4000 [02:17<09:10, 5.81it/s, v_num=0, default_validation/r2=0.746, default_validation/pcc=0.878, default_validation/scc=0.807, default_validation/mae=0.103, default_validation/mse=0.0297, default_validation/rmse=0.172, default_validation/mean=0.178, default_validation/median=0.0845]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.20it/s]
Epoch 2: 40%|████ | 1600/4000 [05:00<07:30, 5.33it/s, v_num=0, default_validation/r2=0.725, default_validation/pcc=0.856, default_validation/scc=0.800, default_validation/mae=0.100, default_validation/mse=0.0314, default_validation/rmse=0.177, default_validation/mean=0.148, default_validation/median=0.0564]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Validation DataLoader 0: 100%|██████████| 250/250 [00:28<00:00, 8.84it/s]
Epoch 2: 60%|██████ | 2400/4000 [07:46<05:10, 5.15it/s, v_num=0, default_validation/r2=0.708, default_validation/pcc=0.864, default_validation/scc=0.818, default_validation/mae=0.100, default_validation/mse=0.0329, default_validation/rmse=0.181, default_validation/mean=0.133, default_validation/median=0.0444]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.23it/s]
Epoch 2: 80%|████████ | 3200/4000 [11:07<02:46, 4.80it/s, v_num=0, default_validation/r2=0.750, default_validation/pcc=0.868, default_validation/scc=0.819, default_validation/mae=0.105, default_validation/mse=0.0291, default_validation/rmse=0.171, default_validation/mean=0.191, default_validation/median=0.0898]
Validation: | | 0/? [00:00<?, ?it/s]
Validation: | | 0/? [00:00<?, ?it/s]
Validation DataLoader 0: 0%| | 0/250 [00:00<?, ?it/s]
Monitored metric default_validation/pcc did not improve in the last 5 records. Best score: 0.871. Signaling Trainer to stop.
Validation DataLoader 0: 100%|██████████| 250/250 [00:24<00:00, 10.21it/s]
Epoch 2: 80%|████████ | 3200/4000 [11:32<02:53, 4.62it/s, v_num=0, default_validation/r2=0.733, default_validation/pcc=0.869, default_validation/scc=0.806, default_validation/mae=0.0985, default_validation/mse=0.0305, default_validation/rmse=0.175, default_validation/mean=0.130, default_validation/median=0.026]
Evaluating the finetuned model performance
Load pretrained ckpt /mnt/Storage/home/chenqianqian/.cache/chrombert/data/checkpoint/hg38_6k_1kb_pretrain.ckpt successfully!
Loading checkpoint from /mnt/Storage2/home/chenqianqian/projects/chrombert/chrombert_tools/ChromBERT-tools/examples/cli/output_cell_specific_emb_train/train/try_00_seed_55/lightning_logs/lightning_logs/version_0/checkpoints/epoch=1-step=126.ckpt
Loading from pl module, remove prefix 'model.'
Loading from pl module, replace 'pretrain_model' with 'pretrain_model.chrombert'
Loaded 111/111 parameters
/mnt/Storage/home/chenqianqian/miniconda3/envs/chrombert/lib/python3.9/site-packages/torchmetrics/utilities/prints.py:43: UserWarning: Metric `SpearmanCorrcoef` will save all targets and predictions in the buffer. For large datasets, this may lead to large memory footprint.
warnings.warn(*args, **kwargs)
ft_ckpt: /mnt/Storage2/home/chenqianqian/projects/chrombert/chrombert_tools/ChromBERT-tools/examples/cli/output_cell_specific_emb_train/train/try_00_seed_55/lightning_logs/lightning_logs/version_0/checkpoints/epoch=1-step=126.ckpt, test_metrics: {'pearsonr': 0.8807425498962402, 'spearmanr': 0.8116908073425293, 'mse': 0.03028654120862484, 'mae': 0.10750571638345718, 'r2': 0.7522819668127768}
Attempt metrics: pearsonr=0.8807425498962402
Accepted run (pearsonr=0.8807 >= 0.4).
Finished stage 2: obtained a fine-tuned ChromBERT
Best pearsonr=0.8807425498962402, metrics={'pearsonr': 0.8807425498962402, 'spearmanr': 0.8116908073425293, 'mse': 0.03028654120862484, 'mae': 0.10750571638345718, 'r2': 0.7522819668127768, 'ft_ckpt': '/mnt/Storage2/home/chenqianqian/projects/chrombert/chrombert_tools/ChromBERT-tools/examples/cli/output_cell_specific_emb_train/train/try_00_seed_55/lightning_logs/lightning_logs/version_0/checkpoints/epoch=1-step=126.ckpt'}
Region summary - total: 100, overlapping with ChromBERT: 101 (one region may overlap multiple ChromBERT regions, we keep overlaps with ≥50% coverage of either the ChromBERT bin or the input region), non-overlapping: 0
Your supervised_file does not contain the 'label' column. Please verify whether ground truth column ('label') is required. If it is not needed, you may disregard this message.
100%|██████████| 26/26 [00:02<00:00, 12.38it/s]
Finished!
Focus region summary - total: 100, overlapping with ChromBERT: 101, non-overlapping: 0
Note: It is possible for a single region to overlap multiple ChromBERT regions.
Overlapping regions BED file: ./output_cell_specific_emb_train/overlap_region.bed
Non-overlapping regions BED file: ./output_cell_specific_emb_train/no_overlap_region.bed
Region embeddings saved to: ./output_cell_specific_emb_train/region_emb_embedding.npy
Embedding type: cell-specific
[ ]:
# region_emb.npy: cell-type-specific region embeddings
import numpy as np
import pandas as pd
overlap_region_emb = np.load("./output_cell_specific_emb_train/region_emb_embedding.npy")
print(overlap_region_emb.shape)
# overlap_region.bed: input regions overlapped with ChromBERT's reference regions; contains columns: chrom, start, end, build_region_index
overlap_region = pd.read_csv("./output_cell_specific_emb_train/overlap_region.bed",sep='\t',header=None, names=['chrom','start','end','build_region_index'])
len(overlap_region),overlap_region.head()
(101, 768)
(101,
chrom start end build_region_index
0 chr1 180791 180871 38
1 chr1 181400 181580 39
2 chr1 182681 182820 40
3 chr1 191400 191540 46
4 chr1 268011 268080 54)
[8]:
# overlap_region.bed: input regions overlapped with ChromBERT's reference regions; contains columns: chrom, start, end, build_region_index, start_input, end_input
model_input = pd.read_csv("./output_cell_specific_emb_train/model_input.tsv",sep='\t')
len(model_input),model_input.head()
[8]:
(101,
chrom start end build_region_index start_input end_input
0 chr1 180000 181000 38 180791 180871
1 chr1 181000 182000 39 181400 181580
2 chr1 182000 183000 40 182681 182820
3 chr1 191000 192000 46 191400 191540
4 chr1 268000 269000 54 268011 268080)
Generate cell-type-specific embeddings using a fine-tuned checkpoint¶
We use a fine-tuned checkpoint as input.
The embed_region subcommand uses this checkpoint to generate cell-type-specific embeddings.
[9]:
import glob
ft_ckpt_dir = "./output_cell_specific_emb_train/train/**/*.ckpt" # Path to the cell-type-specific model checkpoint generated in the previous step
ft_ckpt = glob.glob(ft_ckpt_dir, recursive=True)[0]
ft_ckpt
[9]:
'./output_cell_specific_emb_train/train/try_00_seed_55/lightning_logs/lightning_logs/version_0/checkpoints/epoch=1-step=126.ckpt'
[11]:
# --region: Input regions to embed.
# --odir: Output directory.
# --genome: Genome to use.
# --resolution: Resolution of the input regions.
# --ft-ckpt: Path to the fine-tuned checkpoint.
!chrombert-tools embed_region \
--region ../data/myoblast_ENCFF647RNC_peak_100.bed \
--odir ./output_cell_specific_emb_load_ckpt \
--genome hg38 \
--resolution 1kb \
--ft-ckpt {ft_ckpt}
Using provided fine-tuned checkpoint: ./output_cell_specific_emb_train/train/try_00_seed_55/lightning_logs/lightning_logs/version_0/checkpoints/epoch=1-step=126.ckpt
Load pretrained ckpt /mnt/Storage/home/chenqianqian/.cache/chrombert/data/checkpoint/hg38_6k_1kb_pretrain.ckpt successfully!
Loading checkpoint from ./output_cell_specific_emb_train/train/try_00_seed_55/lightning_logs/lightning_logs/version_0/checkpoints/epoch=1-step=126.ckpt
Loading from pl module, remove prefix 'model.'
Loading from pl module, replace 'pretrain_model' with 'pretrain_model.chrombert'
Loaded 111/111 parameters
Region summary - total: 100, overlapping with ChromBERT: 101 (one region may overlap multiple ChromBERT regions, we keep overlaps with ≥50% coverage of either the ChromBERT bin or the input region), non-overlapping: 0
Your supervised_file does not contain the 'label' column. Please verify whether ground truth column ('label') is required. If it is not needed, you may disregard this message.
100%|███████████████████████████████████████████| 26/26 [00:04<00:00, 5.39it/s]
Finished!
Focus region summary - total: 100, overlapping with ChromBERT: 101, non-overlapping: 0
Note: It is possible for a single region to overlap multiple ChromBERT regions.
Overlapping regions BED file: ./output_cell_specific_emb_load_ckpt/overlap_region.bed
Non-overlapping regions BED file: ./output_cell_specific_emb_load_ckpt/no_overlap_region.bed
Region embeddings saved to: ./output_cell_specific_emb_load_ckpt/region_emb_embedding.npy
Embedding type: cell-specific
[28]:
# region_emb.npy: one 768-dim vector per region
overlap_region_emb2 = np.load("./output_cell_specific_emb_load_ckpt/region_emb_embedding.npy")
print(overlap_region_emb.shape)
# overlap_region.bed: input regions overlapped with ChromBERT's reference regions; contains columns: chrom, start, end, build_region_index
overlap_region2 = pd.read_csv("./output_cell_specific_emb_load_ckpt/overlap_region.bed",sep='\t',header=None, names=['chrom','start','end','build_region_index'])
len(overlap_region),overlap_region.head()
(101, 768)
[28]:
(101,
chrom start end build_region_index
0 chr1 180791 180871 38
1 chr1 181400 181580 39
2 chr1 182681 182820 40
3 chr1 191400 191540 46
4 chr1 268011 268080 54)
[ ]:
assert (overlap_region_emb2 == overlap_region_emb).all() # Check whether the embeddings are the same as those from the model-building step
[ ]: